SQL Server 2019 — Myth or Reality?
If you work with databases, you already know it can be the Pain. If you don’t — you should know that before you start. It is all fun when you start writing SFW (select-from-where) Queries, juggling around with multiple tables, complex conditions, fancy aliases, or stored procedures. The point where the game becomes harder, and the playground has no end is called — Performance.
If performance is under the question mark, there are numerous things you should consider: indexes — are those clustered or non-clustered, composite, or single; a way of joining tables; analysis of execution plans; compile and execution time, and much more.
To make the life of us dealing with SQL performance easier, Microsoft worked on making SQL Server 2019 smarter, faster, and better to use in comparison to its ancestors. Did they succeed? Let’s see.
Microsoft SQL Server 2019 — Theory /boring/
SQL Server 2019 is changing the amount of memory that is granted to query for sorting and comparison. It also introduces scalar function in-lining and deferred compilation for table variables.
Intelligent Query Processing (IQP) — SQL Server 2019 includes built-in query processing capabilities. It includes features with a broad impact that improves the performance of existing workloads with minimal implementation effort to adopt. By updating the database compatibility level to 150 (the default level for SQL Server 2019), the query processor in the SQL Server engine can enhance performance through capabilities like batch-mode on row store, scalar UDF inlining, or table variable deferred compilation. It can automatically correct memory-related query execution issues through memory grant feedback. No or minimal query or application changes are required for a boost in performance.
The following IQP Features are beneficial when it comes to improving the performance of SQL queries:
Adaptive joins — enable the choice of a Hash Join or Nested Loops join method to be deferred until after the first input has been scanned. The Adaptive Join operator defines a threshold that is used to decide when to switch to a Nested Loops plan. A query plan can, therefore, dynamically switch to a better join strategy during execution without having to be recompiled.
Memory grant feedback for both row and batch modes –
Reduce wasted memory — For an excessive memory grant condition, if the granted memory is more than two times the size of the actually used memory, memory grant feedback will recalculate the memory grant. Consecutive executions will then request less memory.
Decrease spills to disk — For an insufficiently sized memory grant that results in a spill to disk, memory grant feedback will trigger a recalculation of the memory grant. Consecutive executions will then request more memory.
Batch Mode on Rowstore — For queries that need aggregations across a large number of rows for which batch processing was designed for, the results in terms of query speed and efficiency are very impressive.
Scalar User-Defined Functions (UDF) inlining — Scalar UDF inlining automatically transforms scalar UDFs into relational expressions. It embeds them in the calling SQL Query.
Lightweight query profiling — SQL Server Database Engine provides the ability to access run-time information on query execution plans. SQL Server 2019 (15.x) includes a newly revised version of lightweight profiling, collecting row count information for all executions. Lightweight profiling is enabled by default on SQL Server 2019 (15.x).
Optimized Insert Performance — SQL Server has long suffered from a bottleneck when trying to insert sequential records into a table at a very high volume. This is because of contention in memory, as only one worker thread can access a data page at a given moment. SQL Server 2019 introduces an optional feature called “optimize_for_sequential_key” that reduces the effect of these bottlenecks.
Security — SQL Server 2019, unlike SQL Server 2016 and SQL Server 2017, is always encrypted with secure enclaves. Additionally, SQL Server 2019 introduces Data Discovery & Classification — a new tool built into SQL Server Management Studio (SSMS) for discovering, classifying, labeling & reporting the sensitive data in your databases. Discovering and classifying your most sensitive data (business, financial, healthcare, etc.) can play a pivotal role in your organizational information protection stature. It can serve as infrastructure for:
– Helping meet data privacy standards.
– Controlling access to and hardening the security of databases/columns containing highly sensitive data.
Proof Of Concept /fun/
Data Source: Adventure Works
For a start, we’ll use data from a well-known sample database — Adventure Works. The following stored procedure has been created and executed against both — SQL Server 2016 and SQL Server 2019:

Results:

Differences displayed in the table above are not that large (SQL Server 2019 has executed the query 1.13 times faster than SQL Server 2016), because this is a simple query with 166.271 records as an output. Larger and more complex queries should result in a bigger difference and better performance. Generally speaking, SQL Server 2019 has a better execution plan even for this simple query:
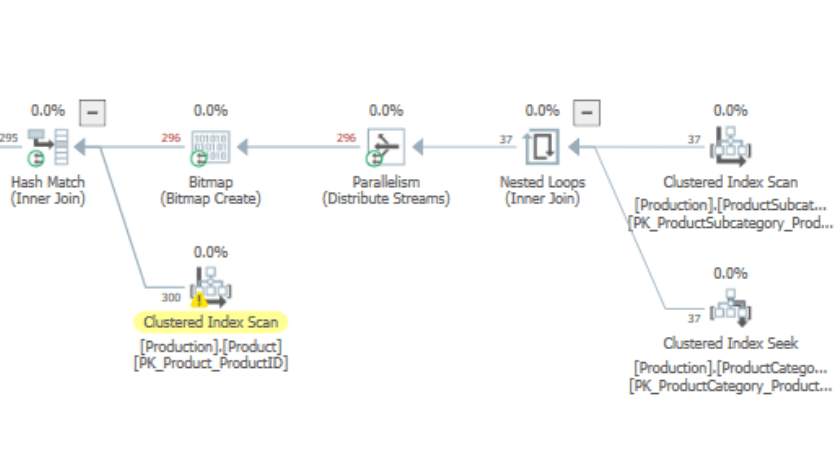
Execution plan — SQL Server 2019
Data Source: Real-world 3rd party database
Since all databases out there are not designed as Adventure Works is I’ve decided to write a query and run it against the database which has the following attributes:
1. The subject database is from a 3rd party application and not managed by the client;
2. The database schema changes when the 3rd party application gets updated;
3. There are multiple clients with the same 3rd party application, but different versions, therefore different database schemes;
4. The update cycles of the 3rd party applications are determined by each client individually;
5. The database is not small, and is growing in size each day;
The following query is run against this database on both SQL Server 2016 and SQL Server 2019:
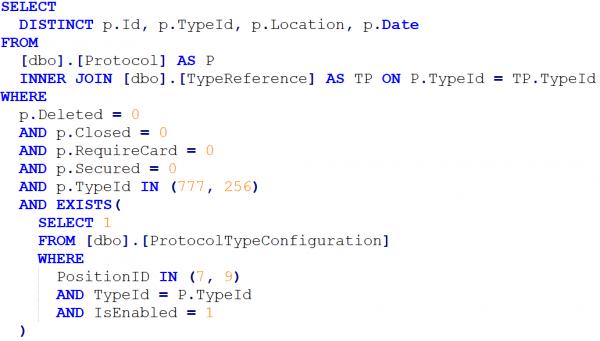
Without any constraints on the database which is on SQL Server 2019, the results are as follows:

SQL Server 2016 vs SQL Server 2019 Execution time (no constraints on SQL Server 2019)
With same constraints on both SQL Server 2016 and SQL Server 2019 databases, the results are as follows:

SQL Server 2016 vs SQL Server 2019 Execution time (same constraints)
Then, I tried to add custom constraints and hoped I will get a strong argument for having custom constraints approved and guess what? The result is incredible:

SQL Server 2016 vs SQL Server 2019 Execution Time (with custom constraints on SQL Server 2019)
Conclusion /long story short/
Microsoft SQL Server 2019 worked a lot on making SQL Server 2019 smarter, faster and better to use in comparison to its ancestors. Did they succeed? If you ask me — Yes!
As you can notice, running the same query against SQL Server 2016 and SQL Server 2019 resulted in having much better performance without any optimization performed:
– Same query; No constraints on SQL Server 2019; Result: SQL Server 2019 is 2.1 times faster
– Same query; Same constraints on both databases; Result: SQL Server 2019 is 2.4 times faster
– Same query; Custom constraints on SQL Server 2019; Result: SQL Server 2019 is 228 times faster
228 times faster sounds incredible, right? Unfortunately, you cannot always add constraints and adjust the database as you want — Even I know 228 times is true and possible, I am happy with 2.4 times faster execution with minimal implementation effort.
SQL Server 2019 — Myth or Reality? For me — so real!